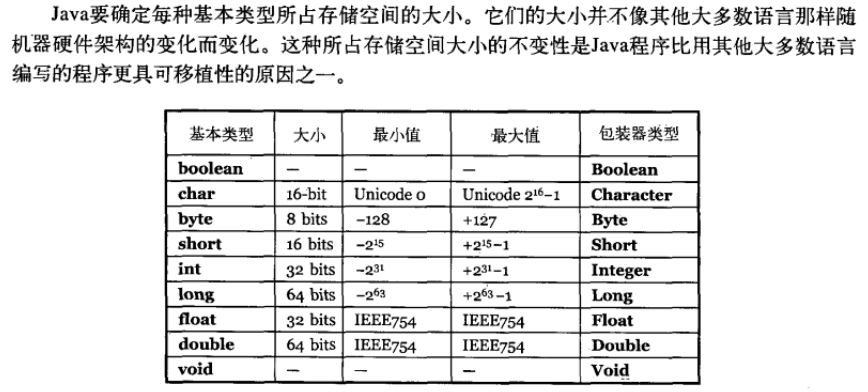
Java 的8种基本数据类型及其大小
Java 基本类型与引用类型的区别
基本类型保存原始值,引用类型保存的是引用值(引用值就是指对象在堆中所 处的位置/地址)
多态的好处
允许不同类对象对同一消息做出响应,即同一消息可以根据发送对象的不同,而采用多种不同的行为方式(发送消息就是函数调用)。主要有以下优点:
- 可替换性:多态对已存在代码具有可替换性
- 可扩充性:增加新的子类不影响已经存在的类结构
- 接口性:多态是超类通过方法签名,向子类提供一个公共接口,由子类来完善或者重写它来实现的。
- 灵活性
- 简化性
代码中如何实现多态
实现多态主要有以下三种方式:
1.接口实现
2.继承父类重写方法
3.同一类中进行方法重载
什么是不可变对象
不可变对象指对象一旦被创建,状态就不能再改变。任何修改都会创建一个新的对象,如String、Integer及其它包装类。
静态变量和实例变量的区别?
静态变量存储在方法区,属于类所有。实例变量存储在堆当中,其引用存在当前线程栈
自动装箱和拆箱
自动装箱是Java 编译器在基本数据类型和对应的对象包装类型之间做的一个转化。
比如:把int转化成 Integer,double转化成 Double,等等。反之就是自动拆箱。
原始类型: boolean,char,byte,short,int,long,float,double
封装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
装箱:将基本类型用它们对应的引用类型包装起来;
拆箱:将包装类型转换为基本数据类型;
字节与字符的区别
字节是存储容量的基本单位。
字符是数字,字母,汉字以及其他语言的各种符号。
1 字节=8 个二进制单位:一个一个字符由一个字节或多个字节的二进制单位组成。
Java 中 IO 流分为几种?
按功能来分:输入流(input)、输出流(output)。
按类型来分:字节流和字符流。
字节流和字符流的区别是:字节流按 8 位传输以字节为单位输入输出数据,字符流按 16 位传输以字符为单位输入输出数据。
既然有了字节流,为什么还要有字符流?
字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
面向对象和面向过程的区别
面向过程:面向过程性能比面向对象高。 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发。但是,面向过程没有面向对象易维护、易复用、易扩展。
面向对象:面向对象易维护、易复用、易扩展。 因为面向对象有封装、继承、多态性的特性,所以可以设计出低耦合的系统,使系统更加灵活、更加易于维护。但是,面向对象性能比面向过程低。
java 当中的四种引用
强引用,软引用,弱引用,虚引用。不同的引用类型主要体现在 GC(Garbage Collection,即垃圾收集) 上:
强引用:如果一个对象具有强引用,它就不会被垃圾回收器回收。即使当前内存空间不足,JVM 也不会回收它,而是抛出 OutOfMemoryError 错误,使程序异常终止。如果想中断强引用和某个对象之间的关联,可以显式地将引用赋值为 null,这样一来的话,JVM 在合适的时间就会回收该对象。
软引用:在使用软引用时,如果内存的空间足够,软引用就能继续被使用,而不会
被垃圾回收器回收,只有在内存不足时,软引用才会被垃圾回收器回收。
弱引用:具有弱引用的对象拥有的生命周期更短暂。因为当 JVM 进行垃圾回收,一旦发现弱引用对象,无论当前内存空间是否充足,都会将弱引用回收。不过由于垃圾回收器是一个优先级较低的线程,所以并不一定能迅速发现弱引用对象。
虚引用:顾名思义,就是形同虚设,如果一个对象仅持有虚引用,那么它相当于没有引用,在任何时候都可能被垃圾回收器回收。
JDK 和 JRE 的区别?
JDK:Java Development Kit 的简称,Java 开发工具包,提供了 Java 的开发环境和运行环境。
JRE:Java Runtime Environment 的简称,Java 运行环境,为 Java 的运行提供了所需环境。 具体来说 JDK 其实包含了 JRE,同时还包含了编译 Java 源码的编译器 Javac,还包含了很多 Java 程序调试和分析的工具。
简单来说:如果你需要运行 Java 程序,只需安装 JRE 就可以了,如果你需要编写 Java 程序,需要安装 JDK。
重载和重写的区别?
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。
重载发生在一个类中,同名的方法如果有不同的参数列表(类型不同、个数不同、顺序不同)则视为重载。
重写发生在子类与父类之间,重写要求子类重写之后的方法与父类被重写方法有相同的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求。
方法重载的规则:
- 方法名一致,参数列表中参数的顺序,类型,个数不同。
- 重载与方法的返回值无关,存在于父类和子类,同类中。
- 可以抛出不同的异常,可以有不同修饰符。
方法重写的规则:
- 参数列表、方法名、返回值类型必须完全一致;
- 构造方法不能被重写;
- 声明为 final 的方法不能被重写;
- 声明为 static 的方法不存在重写(重写和多态联合才有意义);
- 访问权限不能比父类更低;
- 重写之后的方法不能抛出更宽泛的异常;
String 和 StringBuffer、StringBuilder 的区别是什么?
可变性
简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以 String 对象是不可变的。而StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据: 适用String
- 单线程操作字符串缓冲区下操作大量数据: 适用StringBuilder
- 多线程操作字符串缓冲区下操作大量数据: 适用StringBuffer
String类中intern()方法如何实现?
intern()方法设计的初衷,就是重用String对象,以节省内存消耗,也就是会从字符串常量池中首先获取。
注意事项
- 性能开销:虽然
intern()方法可以节省内存,但是在字符串池中查找字符串可能会带来一定的性能开销,特别是在字符串池很大的时候。 - 内存泄漏风险:如果字符串池变得非常大,可能会导致内存泄漏。因此,在使用
intern()方法时需要注意控制字符串池的大小,避免无谓的字符串放入字符串池。
反射机制
Java反射(Reflection)是Java语言的一个重要特性,它允许程序在运行时访问自身的信息,并且可以直接操作对象的字段、方法和构造器。
反射的使用场景
代理模式,JDBC链接数据库,Spring
反射的缺点是什么?如何优化?
缺点: java反射是要解析字节码,将内存中的对象进行解析,包括了一些动态类型,所以JVM无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多!
提高反射性能的方式有哪些?
- setAccessible(true),可以防止安全性检查(做这个很费时)
- 做缓存,把要经常访问的元数据信息放入内存中,class.forName 太耗时
- getMethods() 等方法尽量少用,尽量调用getMethod(name)指定方法的名称,减少遍历次数
静态代理模式和动态代理模式的区别
静态: 由程序员创建代理类。在程序运行前要代理的对象就已经指定了。
动态: 在程序运行时运用反射机制动态创建而成。(InvocationHandler的应用)
JDK动态代理和CGLIB动态代理的区别
SpringAOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理:
(1)JDK动态代理只提供接口的代理,不支持类的代理。核心InvocationHandler接口和Proxy类,InvocationHandler通过invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy利用InvocationHandler动态创建一个符合某一接口的的实例,生成目标类的代理对象。
(2)如果代理类没有实现InvocationHandler接口,那么SpringAOP会选择使用CGLIB来动态代理目标类。CGLIB(CodeGenerationLibrary),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
静态代理与动态代理区别在于生成AOP代理对象的时机不同,相对来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译器进行处理,而SpringAOP则无需特定的编译器处理。
反射 Class.forName 和 classLoader有什么区别
第一:Class.forName(“className”);
其实这种方法调运的是:Class.forName(className,true,ClassLoader.getCallerClassLoader())方法
- 参数一:className,需要加载的类的名称。
- 参数二:true,是否对class进行初始化(需要initialize)
- 参数三:classLoader,对应的类加载器。如果没有提供类加载器,默认情况调用线程的上下文类加载器
第二:ClassLoader.loadClass(“className”);
其实这种方法调运的是:ClassLoader.loadClass(name,false)方法
- 参数一:name,需要加载的类的名称
- 参数二:false,这个类加载以后是否需要去连接(不需要linking)
第三:区别
可见Class.forName除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
而classloader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
抽象类和接口的区别
实现:抽象类的子类使用 extends 来继承;接口必须使用 implements 来实现接口。
构造函数:抽象类可以有构造函数;接口不能有。
实现数量:类可以实现很多个接口;但只能继承一个抽象类【java只支持单继承】。
访问修饰符:接口中的方法默认使用 public 修饰;抽象类中的抽象方法可以使用Public和Protected修饰,如果抽象方法修饰符为Private,则报错:The abstract method 方法名 in type Test can only set a visibility modifier, one of public or protected。
接口中除了static、final变量,不能有其他变量,而抽象类中则不一定
设计层面:抽象是对类的抽象,是一种模板设计,而接口是对行为的抽象,是一种行为的规范。
普通类和抽象类有哪些区别?
普通类不能包含抽象方法,抽象类可以包含抽象方法。
抽象类是不能被实例化的,就是不能用new调出构造方法创建对象,普通类可以直接实例化。
如果一个类继承于抽象类,则该子类必须实现父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为abstract类。
抽象类必须要有抽象方法吗?
不需要,抽象类不一定非要有抽象方法;但是包含一个抽象方法的类一定是抽象类。
抽象类能使用 final 修饰吗?
不能,定义抽象类就是让其他类继承的,如果定义为 final 该类就不能被继承,这样彼此就会产生矛盾,所以 final 不能修饰抽象类。
final有哪些用法
final也是很多面试喜欢问的地方,能回答下以下三点就不错了:
1.被final修饰的类不可以被继承
2.被final修饰的方法不可以被重写
3.被final修饰的变量不可以被改变。如果修饰引用,那么表示引用不可变,引用指向的内容可变。
4.被final修饰的方法,JVM会尝试将其内联,以提高运行效率
5.被final修饰的常量,在编译阶段会存入常量池中。
构造方法有哪些特性?
- 名字与类名相同。
- 没有返回值,但不能用void声明构造函数。
- 生成类的对象时自动执行,无需调用。
静态方法和实例方法有何不同
在外部调用静态方法时,可以使用“类名.方法名”的方式,也可以使用“对象名.方法名”的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
static 关键字的理解?
修饰成员变量和成员方法: 被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享,可以并且建议通过类名调用。被static 声明的成员变量属于静态成员变量,静态变量 存放在 Java 内存区域的方法区。调用格式:类名.静态变量名 类名.静态方法名()静态代码块: 静态代码块定义在类中方法外, 静态代码块在非静态代码块之前执行(静态代码块—>非静态代码块—>构造方法)。 该类不管创建多少对象,静态代码块只执行一次.静态内部类(static修饰类的话只能修饰内部类): 静态内部类与非静态内部类之间存在一个最大的区别: 非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围类,但是静态内部类却没有。没有这个引用就意味着:1. 它的创建是不需要依赖外围类的创建。2. 它不能使用任何外围类的非static成员变量和方法。静态导包(用来导入类中的静态资源,1.5之后的新特性): 格式为:import static 这两个关键字连用可以指定导入某个类中的指定静态资源,并且不需要使用类名调用类中静态成员,可以直接使用类中静态成员变量和成员方法。
super 关键字的理解
super关键字用于从子类访问父类的变量和方法。 例如:
public class Super {
protected int number;
protected showNumber() {
System.out.println("number = " + number);
}
}
public class Sub extends Super {
void bar() {
super.number = 10;
super.showNumber();
}
}
在上面的例子中,Sub 类访问父类成员变量 number 并调用其其父类 Super 的 showNumber() 方法。
使用 this 和 super 要注意的问题:
- 在构造器中使用 super() 调用父类中的其他构造方法时,该语句必须处于构造器的首行,否则编译器会报错。另外,this 调用本类中的其他构造方法时,也要放在首行。
- this、super不能用在static方法中。
简单解释一下:
被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享。而 this 代表对本类对象的引用,指向本类对象;而 super 代表对父类对象的引用,指向父类对象;所以, this和super是属于对象范畴的东西,而静态方法是属于类范畴的东西。
常见的异常类有哪些
NullPointerException 空指针异常
ClassNotFoundException 指定类不存在
NumberFormatException 字符串转换为数字异常
IndexOutOfBoundsException 数组下标越界异常
ClassCastException 数据类型转换异常
FileNotFoundException 文件未找到异常
NoSuchMethodException 方法不存在异常
IOException IO 异常
SocketException Socket 异常
3*0.1==0.3返回值是什么
false,因为有些浮点数不能完全精确的表示出来。
shorts1=1;s1=s1+1;该段代码是否有错,有的话怎么改?
有错误,short类型在进行运算时会自动提升为int类型,也就是说s1+1的运算结果是int类型。
shorts1=1;s1+=1;该段代码是否有错,有的话怎么改?
+=操作符会自动对右边的表达式结果强转匹配左边的数据类型,所以没错。
comparable 和 Comparator的区别
- comparable接口实际上是出自java.lang包 它有一个 compareTo(Object obj)方法用来排序
- comparator接口实际上是出自 java.util 包它有一个compare(Object obj1, Object obj2)方法用来排序
一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo()方法或compare()方法,当我们需要对某一个集合实现两种排序方式,比如一个song对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo()方法和使用自制的Comparator方法或者以两个Comparator来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 Collections.sort().
Comparable是让对象自身具备比较性,而Comparator则是通过外部比较器来定义比较规则。
String str=”i”与 String str=new String(“i”)一样吗?
不一样,因为内存的分配方式不一样。String str=“i”的方式,Java 虚拟机会将其分配到常量池中,如果常量池中有”i”,就返回”i”的地址,如果没有就创建”i”,然后返回”i”的地址;而 String str=new String(“i”) 则会被分到堆内存中新开辟一块空间。
String 属于基础的数据类型吗?
String 不属于基础类型,基础类型有 8 种:byte、boolean、char、short、int、float、long、double,而 String 属于对象。
final 在 Java 中有什么作用?
final 修饰的类叫最终类,该类不能被继承。
final 修饰的方法不能被重写。
final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
两个对象的 hashCode() 相同,则 equals() 也一定为 true,对吗?
不对,两个对象的 hashCode() 相同,equals() 不一定 true。
hashCode()介绍
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object.java 中,这就意味着 Java 中的任何类都包含有 hashCode() 函
数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高
了执行速度。
hashCode()与 equals()的相关规定
- 如果两个对象相等,则 hashcode 一定也是相同的
- 两个对象相等,对两个对象分别调用 equals 方法都返回 true
- 两个对象有相同的 hashcode 值,它们也不一定是相等的
- 因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
- hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写
hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
== 与 equals 的区别?
== 解读:
对于基本类型和引用类型 == 的作用效果是不同的,如下所示:
基本类型:比较的是值是否相同; 引用类型:比较的是引用是否相同; 代码示例:
String x = "string";
String y = "string";
String z = new String("string");
System.out.println(x==y); // true
System.out.println(x==z); // false
System.out.println(x.equals(y)); // true
System.out.println(x.equals(z)); // true
代码解读:因为 x 和 y 指向的是同一个引用,所以 == 也是 true,而 new String()方法则重写开辟了内存空间,所以 == 结果为 false,而 equals 比较的一直是值,所以结果都为 true。
equals 解读:
equals 本质上就是 ==,只不过 String 和 Integer 等重写了 equals 方法,把它变成了值比较。看下面的代码就明白了。
首先来看默认情况下 equals 比较一个有相同值的对象,代码如下:
class Cat {
public Cat(String name) {
this.name = name;
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Cat c1 = new Cat("精彩猿笔记");
Cat c2 = new Cat("精彩猿笔记");
System.out.println(c1.equals(c2)); // false
输出结果出乎我们的意料,竟然是 false?这是怎么回事,看了 equals 源码就知道了,源码如下:
public boolean equals(Object obj) {
return (this == obj);
}
原来 equals 本质上就是 ==。 那问题来了,两个相同值的 String 对象,为什么返回的是 true?代码如下:
String s1 = new String("精彩猿笔记");
String s2 = new String("精彩猿笔记");
System.out.println(s1.equals(s2)); // true
同样的,当我们进入 String 的 equals 方法,找到了答案,代码如下:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
原来是 String 重写了 Object 的 equals 方法,把引用比较改成了值比较。
总结 :== 对于基本类型来说是值比较,对于引用类型来说是比较的是引用;而 equals 默认情况下是引用比较,只是很多类重新了 equals 方法,比如 String、Integer 等把它变成了值比较,所以一般情况下 equals 比较的是值是否相等。
什么是 Java 序列化?什么情况下需要序列化?
Java 序列化是为了保存各种对象在内存中的状态,并且可以把保存的对象状态再读出来。
以下情况需要使用 Java 序列化:
想把的内存中的对象状态保存到一个文件中或者数据库中时候;
想用套接字在网络上传送对象的时候;
想通过RMI(远程方法调用)传输对象的时候。
Java序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用transient关键字修饰。
transient关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被transient修饰的变量值不会被持久化和恢复。transient只能修饰变量,不能修饰类和方法。
深拷贝和浅拷贝的区别是什么?
浅拷贝:被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。换言之,浅拷贝仅仅复制所考虑的对象,而不复制它所引用的对象。
深拷贝:被复制对象的所有变量都含有与原来的对象相同的值,而那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。换言之,深拷贝把要复制的对象和它所引用的对象都进行了复制。
BIO、NIO、AIO 有什么区别?
- BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
- NIO (New I/O): NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
- AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。







